
https://arxiv.org/pdf/2205.00159
Abstract
이전까지 text recognition model은 이미지의 특징을 뽑는 visual model과 텍스트를 변환하는 sequence model을 포함했다. 이 연구에서는 이를 하나로 합친 모델을 소개한다.
SVTR은 이미지를 작은 패치(charater components)로 분해하고, component-level의 혼합, 병합, 결합을 통해 계층적 단계가 반복된다. Globel, local mixing blocks은 문자내 패턴을 인식하도록 고안되어 다중 세분화된 문자 구성 요소 인식으로 이어진다. 따라서 간단한 선형 예측을 통해 문자를 인식 한다.
SVRT-L(Large)는 영어와 중국어에서 높은 정확도를 기록했고 SVRT-T(Tiny)는 훨씬 작은 모델로 빠른 속도를 보여준다.
코드는 https://github.com/PaddlePaddle/PaddleOCR 에 공개되어있다.
1. Introduction
- 기존 모델과의 비교
- CNN-RNN-pred
- the reshaping is sensitive to text disturbances such as deformation, occlusion, etc, limiting their effectiveness.
- CNN/MHSA - RNN/MHA -pred
- the inference speed is slow due to the character-by-character transcription
- CNN/MHSA-Pred-MHA-pred
- the pipeline often requires a large capacity model or complex recognition paradigm to ensure the recognition accuracy, restricting its efficiency
- SVTR-pred
- SVTR은 기존의 CNN 백본을 제거하고, 대신 단일 트랜스포머로만 텍스트 이미지를 처리. 이를 통해 전역적인 특징 추출을 더 효율적으로 수행하며, 복잡한 텍스트 구조와 다양한 글자 형태에도 유연하게 대응.
- CNN-RNN-pred
2. Method
2.1 overall architecture
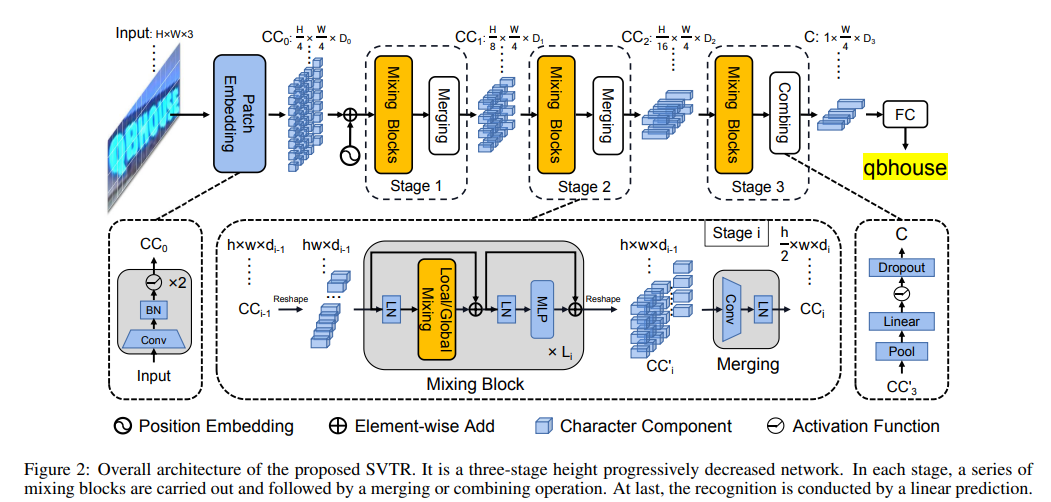
- HXWX3 크기의 이미지 텍스트가 D0의 H/4 x H/4 패치로 변환
- 일련의 mixing blocks(followed by a merging or combining operation) 서로 다른 규모로 수행 → 특징 추출
- Local 및 Global mixing blocks(stroke와 유사한 로컬 패턴 추출, 구성요소간 의존성 캡처를 위함)
- 백본을 사용하면 다양한 거리와 여러 스케일에서 구성 요소 특징과 의존성이 특성화되어 다중 입자 문자 특징을 인식하는 크기 1 × D3의 C라고 하는 표현이 생성
- 문자 시퀀스를 얻기 위해 중복 제거가 포함된 병렬 선형 예측이 수행
2.2 Progressive Overlapping Patch Embedding

트랜스포머 모델의 입력으로 변환하는 데는 두가지 방법이 있다.
- (a)는 단순히 이미지 패치를 선형 투영을 통해 트랜스포머 입력으로 변환하는 방식.
- (b)는 컨볼루션 층을 사용하여 점진적으로 특징을 추출하고, 피처 융합을 통해 보다 복잡한 특징을 생성하는 방식.
2.3 Mixing Block
기존의 1차원 시퀀스 특징은 불규칙한 텍스트에서 노이즈가 많아지고, 문자 자체를 잘 설명하지 못하는 문제가 있었다. 이를 개선하기 위해 2차원 특징 표현 방식(vision Transformer의 발전으로..)을 텍스트 인식에 적용한다.
문자 인식을 위한 두가지 특징에는 지역적 특징(stroke와 같은)과 문자 간 의존성이 있다.
- 지역적 특징 문자의 구성 요소들 사이의 관계를 인코딩하는 것. 예를 들어, 획(stroke) 같은 특징을 통해 문자의 형태적 특징을 표현
- 문자 간 의존성 서로 다른 문자들 또는 문자와 비문자 사이의 관계를 표현
텍스트 인식에서 문자의 구성 요소 간의 상관성을 인식하기 위해 두 가지 혼합 블록(mixing blocks)이 설계되었다. 이들은 서로 다른 수용 영역(receptive fields)에서 self-attention을 사용하여 텍스트 인식의 정확도를 높이는 데 기여한다.

전역혼합(a)는 모든 문자 구성 요소 간의 종속성을 평가한다.
- 주요 목표: 텍스트와 비텍스트 요소를 구분하여 비텍스트 요소의 영향을 약화시키고, 텍스트 요소의 중요성을 높임.
- 구조: 먼저 문자 구성 요소들이 특징 시퀀스로 변환. 이후 layer norm과 multi-head self-attention을 적용해 구성 요소 간의 의존성을 모델링 → MLP가 사용되어 특징을 융합 → shortcut connection을 통해 정보 손실을 방지
지역 혼합(b)은 각 문자 내에서 인접한 구성 요소들 간의 상관성을 평가한다.
- 주요 목표: 문자의 세밀한 구조적 특징을 인식하고, stroke와 같은 문자의 형태적 패턴을 인코딩
- 구조: 각 구성 요소 주변의 이웃을 고려하며, 슬라이딩 윈도우 방식으로 혼합. 윈도우 크기는 7x11로 설정되며, 이는 각 문자의 세부적인 패턴을 캡처하기 위함 지역 혼합은 self-attention을 활용하여 지역적 패턴 인식
전역 혼합과 지역 혼합 블록은 상호 보완적인 특징을 추출하기 위해 설계되었으며 SVTR 모델에서 반복 적용되어 문자 인식을 위한 특징을 추출한다.
2.4 Merging
텍스트 인식 모델에서 각 단계마다 일정한 공간 해상도를 유지하는 것은 계산 비용이 많이 든다. 또 불필요한 중복 정보를 발생시킬수 있다.
따라서 혼합블록은 병합 연산을 사용하여 공간해상도를 조절한다.
연산 과정
- 혼합 블록에서 출력된 특징 맵을 j*w*d_{i-1} 크기의 임베딩으로 변환
- 3x3 컨볼루션을 사용해 높이는 절반으로(stride 2), 너비는 유지 (stride 1)
- 레이어 정규화 적용 h/2×w×d_i 크기의 임베딩 생성
병합 작업은 높이를 절반으로 줄이면서 너비는 유지하여, 계산 비용을 줄이면서 텍스트 인식에 맞춘 계층적 구조를 구축한다. 대부분 텍스트는 수평으로 나타나기 때문에 높이만 줄이는 것이 효율적이다. (높이를 압축하면 각문자에 대한 다중 스케일 표현 형성 가능. 너비를 유지하면 인접한 문자가 혼합되어 잘못 인식될 가능성 줄어듬)
높이를 줄임으로 인해 손실된 정보를 보안하기 위해 채널 차원을(d_i) 증가시킨다.
2.5 Combining and Prediction
마지막 단계에선 병합작업이 결합작업(combining operation)으로 대체된다.
결합작업
- 높이차원을 1로 pooling (=이미지를 높이 차원에서 하나로 압축)
- fully-connected later, non-linear acitvation, drop out을 적용하여 텍스트를 압축된 특징 시퀀스로 변환 (특징 시퀀스의 각 요소는 D_3 길이의 특징으로 표현)
병합 작업과 달리, 결합 작업은 매우 작은 높이 차원을 가진 경우(예: 높이가 2인 경우) 컨볼루션을 적용할 필요가 없어서 연산량을 줄일 수 있다.
결합된 특징을 사용하여 단순한 병렬 선형 예측 모델로 텍스트 인식을 수행한다. N 노드를 가진 선형분류기로 텍스트를 인식한다. (영어의 경우 N=37, 중국어의 경우 N=6625) 이 분류기는 W/4크기의 시퀀스를 생성한다. 시퀀스에서 같은 문자의 구성요소는 중복된 문자로 변환되고 텍스트가 아닌 구성요소는 공백기호로 변환된다. 이과정은 자동으로 최종결과로 압축된다.
2.6 Architecture Variants

- SVTR 아키텍처의 하이퍼파라미터:
- 채널의 깊이(depth of channel)와 각 단계에서의 헤드 수(number of heads)를 포함
- 각 단계에서 혼합 블록(mixing blocks)의 수와 그 순서(permutation)를 설명
- SVTR의 다양한 용량:
- 이러한 변수들을 조절하여 SVTR 아키텍처를 다양한 크기로 만들 수 있음
- SVTR-T (Tiny), SVTR-S (Small), SVTR-B (Base), SVTR-L (Large) 4개의 대표적인 모델이 구성됨
3. Experiments
3.1 Datasets
1. 영어 텍스트 인식
모델은 두 개의 널리 사용되는 합성 텍스트 데이터셋에서 학습된다
- MJSynth (MJ): Jaderberg et al., 2014, 2015에서 제공된 합성 텍스트 데이터셋.
- SynthText (ST): Gupta et al., 2016에서 제공된 합성 텍스트 데이터셋.
이후 모델은 아래의 6개의 공개 벤치마크 데이터셋에서 테스트된다:
- ICDAR 2013 (IC13):
- Karatzas et al., 2013이 제안한 데이터셋으로, 1095개의 테스트 이미지가 포함.
- 알파벳 및 숫자 이외의 문자를 포함하는 이미지나 3자 미만의 문자를 포함하는 이미지는 제외되며, 최종적으로 857개의 이미지가 사용.
- Street View Text (SVT):
- Wang et al., 2011이 제안한 데이터셋으로, 647개의 테스트 이미지를 포함.
- 구글 스트리트 뷰에서 잘려 나온 이미지이며, 일부 이미지는 노이즈, 흐림, 저해상도로 심각하게 손상.
- IIIT5K-Words (IIIT):
- Mishra et al., 2012가 제안한 데이터셋으로, 웹사이트에서 수집된 이미지들이 포함되며, 3000개의 테스트 이미지를 포함.
- ICDAR 2015 (IC15):
- Karatzas et al., 2015이 제안한 데이터셋으로, 구글 글래스로 찍은 이미지로 포커스와 위치를 제대로 맞추지 않은 상태에서 촬영된 이미지가 포함.
- 1811개의 이미지와 2077개의 이미지를 포함한 두 가지 버전이 있으며, 본 연구에서는 첫 번째 버전을 사용.
- Street View Text-Perspective (SVTP):
- Phan et al., 2013이 제안한 데이터셋으로, 구글 스트리트 뷰에서 잘려 나온 이미지들이 포함.
- 이 데이터셋에는 639개의 테스트 이미지가 있으며, 대부분의 이미지가 원근법적으로 왜곡됨.
- CUTE80 (CUTE):
- Anhar et al., 2014이 제안한 데이터셋으로, 곡선형 텍스트 인식을 위한 데이터셋.
- 288개의 테스트 이미지를 포함하며, 주석이 달린 단어를 사용하여 전체 이미지에서 잘려 나온 텍스트가 포함.
2. 중국어 텍스트 인식
- Chinese Scene Dataset:
- Chen et al., 2021이 제안한 공개 데이터셋으로, 509,164개의 학습 이미지, 63,645개의 검증 이미지, 63,646개의 테스트 이미지를 포함.
- 검증 세트는 최상의 모델을 결정하는 데 사용되며, 최종적으로 테스트 세트에서 평가가 이루어짐.
3.2 Implementation Details
SVTR 모델의 구현 세부사항
- Rectification Module: SVTR은 이미지 텍스트 왜곡을 수정하기 위한 정규화 모듈을 사용. 이미지 크기는 32 x 64로 리사이즈되며, 텍스트 왜곡 보정을 수행.
- Optimizer and Learning Rate: AdamW 옵티마이저가 사용되며, weight decay는 0.05로 설정. 훈련에 사용되는 학습률은 코사인 학습률 스케줄러에 따라 조정됨. 영어 모델의 경우, 21개의 에포크에서 2 에포크 동안 학습률이 서서히 증가하는 warm-up 방식이 적용.
- Data Augmentation: 모델 훈련 중 데이터 증강이 적용. 회전, 원근 왜곡, 모션 블러, 가우시안 노이즈와 같은 다양한 증강 기법을 통해 데이터의 다양성을 높임
- Input Length: 영어 모델의 경우 최대 텍스트 길이는 25로 설정. 중국어 모델의 경우, 초기 학습률은 5 에포크 동안 warm-up되고, 총 100 에포크 동안 학습이 진행됨.
- Training Environment: 모든 모델은 Tesla V100 GPU에서 PaddlePaddle 프레임워크를 사용하여 훈련됨
3.3 Ablation Study
소거 연구는 모델의 각 구성 요소가 최종 성능에 미치는 영향을 분석하는 실험이다. 여기서는 패치 임베딩 방식과 혼합 블록의 순서를 변경하며 성능을 비교하는 실험을 진행했다.
The Effectiveness of Patch Embedding (패치 임베딩의 효과)
SVTR에서는 패치 임베딩 방식이 중요한 역할을 한다.
- Linear Embedding: 단순한 선형 임베딩 방식은 IC13에서 92.5%, IC15에서 72.0%의 정확도를 보임
- Overlap Embedding: 중첩 임베딩 방식은 약간 더 나은 성능을 보였지만, 여전히 제안된 방식보다는 낮다
- Proposed Method (제안된 방식): 이 연구에서 제안된 패치 임베딩 방식은 IC13에서 93.5%, IC15에서 74.8%로 가장 높은 성능을 보임. 이 방식은 불규칙한 텍스트에서 특히 효과적임을 보여줌.
The Effectiveness of Merging (병합의 효과)
Merging은 여러 레이어에서 공간 해상도를 유지하는 것이 계산 비용이 많이 든다는 문제를 해결하기 위해 사용되는 방식. 병합을 적용하면 텍스트 인식에서 멀티스케일 샘플링을 구축할 수 있다. 병합을 통해 계산 비용을 줄이면서도 성능 향상을 도모한다.
- None: 병합을 적용하지 않고, 고정된 공간 해상도를 유지하는 방식.
- Progressive Merging: 병합을 적용하여 점진적으로 공간 해상도를 감소시키는 방식. 이 방식은 계산 비용을 줄일 뿐 아니라, 인식 정확도도 향상시킨다.
The Permutation of Mixing Blocks (혼합 블록 순열)
혼합 블록은 전역 혼합(Global Mixing)과 로컬 혼합(Local Mixing)으로 구성된다. 이 두 블록의 순서를 변경하며 성능을 실험한 결과는 아래와 같다.

- Global First: 전역 혼합 블록을 적용한 경우, 각 레이어에서 6개의 전역 혼합 블록이 적용. 이 방식은 인식 성능이 좋지만, 일부 시나리오에서는 로컬 패턴을 잡아내는 데에 한계가 있을 수 있다.
- Local First: 로컬 혼합 블록을 먼저 적용한 경우, 로컬 패턴을 인식하는 데 유리하므로 텍스트 인식에서 중요한 세부 패턴을 잡아내는 데 유리. 특히 불규칙한 텍스트에 대해 더 나은 성능을 발휘.
- Combined Approach: 전역 혼합과 로컬 혼합을 조합하여 사용하는 방식은 가장 종합적인 성능을 제공.
이 실험은 SVTR에서 혼합 블록의 배치 순서가 성능에 미치는 영향을 보여주며, 로컬 패턴을 먼저 처리한 후 전역 패턴을 처리하는 방식이 특히 유리하다
3.4 Comparison with State-of-the-Art
SVTR을 사용한 모델의 성능을 다른 최신 기술(State-of-the-Art)과 비교한다.
SVTR은 영어와 중국어 벤치마크에서 테스트되었으며, 영어 벤치마크에서는 규칙적(regular)과 불규칙(irregular) 텍스트를 모두 포함한 6개의 데이터셋(IC13, SVT, IIIT5K 등)을 사용했다. 이들 데이터셋에서, 특히 불규칙 텍스트에서는 기존 언어 정보(language-aware)를 활용한 모델과 비교해도 SVTR-L이 더 나은 성능을 보여줬습니다. 특히 SVTR-L 모델은 IIIT, IC15, CUTE 데이터셋에서 기존 모델 대비 정확도를 크게 향상시켰다.

SVTR-L의 주요 장점 중 하나는 단일 시각 모델(single visual model)을 사용하면서도 높은 성능을 유지할 수 있다는 점입니다. 이는 문자 구성 요소(character component)를 더 세밀하게 인식하고, 글자와 글자 간의 관계를 잘 파악할 수 있기 때문이다.
또한, SVTR은 중국어 데이터셋에서도 우수한 성능을 발휘했다. 특히 SAR(Supervised Autoencoding Reconstruction) 모델과 비교해, SVTR의 정확도가 5.4%에서 9.6%까지 개선되었습니다. 이는 중국어의 복잡한 문자 구성 요소를 SVTR이 효과적으로 인식했기 때문이다.
3.5 Visualization Analysis
이 섹션에서는 SVTR-T의Attention Maps을 시각화해 분석한다. 어텐션 맵은 SVTR이 텍스트 인식을 할 때 어떤 영역에 주목하는지를 시각적으로 보여준다.
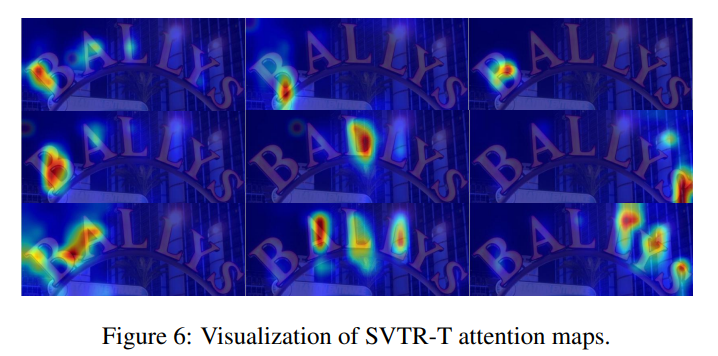
첫 번째 줄은 "B" 문자에 대한 주목을 보여준다. 이 맵은 문자의 왼쪽, 하단, 가운데 부분에 집중하며, 각각의 부분이 인식 과정에 어떻게 기여하는지를 나타낸다.
두 번째 줄은 "B", "L", "S" 문자를 인식하는 과정을 시각화한 맵으로, 서브-캐릭터 수준에서의 분석을 보여준다.
이 어텐션 맵을 통해 SVTR이 다양한 문자 구성 요소와 문자 간의 상호 의존성을 효과적으로 인식할 수 있음을 확인할 수 있다. 더 나아가, SVTR이 서브-캐릭터, 캐릭터 레벨, 크로스-캐릭터의 정보를 모두 효과적으로 결합하여 텍스트 인식을 수행한다는 것을 보여준다.
4. Conclusion
이 논문에서는 장면 텍스트 인식을 위한 맞춤형 시각적 모델인 SVTR을 제시한다. SVTR은 다중 입자 문자 특징을 추출한다. (다중 입자 문자 특징은 여러 높이 척도에서 다양한 거리의 스트로크와 같은 로컬 패턴과 구성 요소 간 의존성을 모두 설명한다.) 따라서 단일 시각적 모델을 사용하여 정확도, 효율성 및 다국어 다재다능함의 장점을 활용하여 인식 작업을 수행할 수 있다.
다양한 애플리케이션 요구 사항을 충족하기 위해 다양한 용량의 SVTR도 고안되었다. 영어와 중국어 벤치마크에 대한 실험은 기본적으로 제안된 SVTR을 검증한다.