AI
NER(Named Entity Recognition) : 한국어 개체명 인식
✿(๑❛ڡ❛๑)✿
2024. 11. 13. 17:31
728x90
SMALL
🐹 NER이란?
단어를 보고 그 단어의 유형을 인식하는것을 말한다.
이는 문장에서 시간, 장소, 객체 나 사람등을 태깅한다.
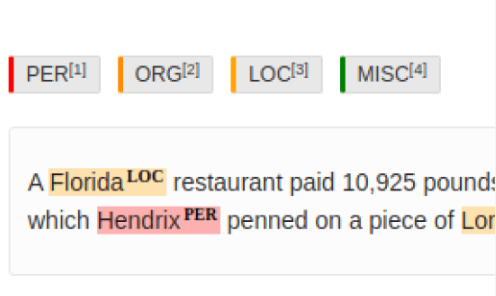
🐹 개체명 태깅
- BIESO 시스템 개체명의 시작에 B, 중간에 I, 마지막에 E를 붙인다. 하나의 토큰으로 이루어진 경우 S를 붙인다. 토큰이 개체명이 아닐 경우에는 O를 붙인다.
- BIO 시스템 E를 I로, S를 B로 단순화 해서 표현한다.
🐹 한국어 NER 테스트
huggingface에 올라와있는 모델을 이용해 테스트 해보았다.
https://huggingface.co/monologg/koelectra-small-finetuned-naver-ner
monologg/koelectra-small-finetuned-naver-ner · Hugging Face
No model card New: Create and edit this model card directly on the website! Contribute a Model Card
huggingface.co
naver에서 제공된 데이터 셋으로 finetuning되었고, 이는 상업적 이용이 제한되어있다.
태깅은 BIO 시스템을 따르며 엔터티는 아래와 같다.
PER: 사람(Person).
FLD: 학문 분야(Field).
AFW: 인공물(Artifactual Work, 예: 책, 영화 등).
ORG: 조직(Organization).
LOC: 장소(Location).
CVL: 시민권 관련(Civil).
DAT: 날짜(Date).
TIM: 시간(Time).
NUM: 숫자(Number).
EVT: 사건(Event).
ANM: 동물(Animal).
PLT: 식물(Plant).
MAT: 물질(Material).
TRM: 용어(Term).
간단하게 testcode를 작성해서 성능을 확인해봤다
from transformers import AutoTokenizer, AutoModelForTokenClassification, pipeline
# 모델 및 토크나이저 로드
model_name = "monologg/koelectra-small-finetuned-naver-ner"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForTokenClassification.from_pretrained(model_name)
# NER 파이프라인 생성
ner_pipeline = pipeline("ner", model=model, tokenizer=tokenizer)
# 테스트 문장
text="민지와 24일 서울에서 만난다."
# NER 수행
results = ner_pipeline(text)
# 결과 출력
for entity in results:
print(f"단어: {entity['word']}, 개체명: {entity['entity']}, 점수: {entity['score']:.4f}")
아래와 같이 비교적 잘 인식하는 것을 확인할 수 있었다.
단어: 민, 개체명: PER-B, 점수: 0.9987
단어: ##지와, 개체명: PER-I, 점수: 0.8643
단어: 24일, 개체명: DAT-B, 점수: 0.9998
단어: 서울에서, 개체명: LOC-B, 점수: 0.9989728x90
LIST