
728x90
SMALL
Temporal-Difference (TD) Learning
강화 학습의 기본 알고리즘 중 하나로, Monte Carlo와 Dynamic Programming 기법의 장점을 통합하여 사용한다.
상태 가치 함수를 한 단계에서 업데이트한다.

긴 에피소드에 대해 동작한다.(몬테가를로는 동작 X)
SARSA: on polict TD control
On-Policy TD 학습 알고리즘 : 현재 정책에 따라 다음 행동 선택
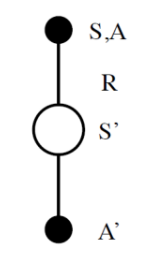
첫 상태 S0을 임의로 샘플링 후 €-soft greedy policy에 따라 행동 A0을 선택한다.

Q-Learning : off polict TD control
첫 상태 S0을 임의로 샘플링 후 €-soft greedy policy에 따라 행동 A0을 선택한다.

728x90
LIST
'SKT FLY AI > Reinforcement Learning' 카테고리의 다른 글
| Reinforcement Learning(4) Monte-Carlo RL (0) | 2024.07.17 |
|---|---|
| Reinforcement Learning (3) Markov Decision Process (0) | 2024.07.17 |
| Reinforcement Learning (2) Backpropagation (0) | 2024.07.17 |
| Reinforcement Learning (1) Intro (2) | 2024.07.17 |